

AI transcription’s main selling point, aside from speed, has always been near-human accuracy. Specifically, they advertise “95% accurate”, which may sound sufficient. But it’s that 5% is where many risks lie, and it beats the purpose of having transcripts. What’s tricky is that when these errors manifest in narrow linguistic zones where meaning is dense, the consequences are high. Examples include a misheard person’s name, drug name, or a corrupted number that completely changes the record’s interpretation. This is why critical workflows that involve legal transcription services prefer a human review rather than relying solely on AI alternatives.
Right now, the question is not whether AI transcription works – some work better than others. But it also almost always breaks. When these failures occur, they do not come in one single section. Errors spread throughout the whole transcript, affecting even the sensitive parts of communication.
The Illusion of Uniform Accuracy
When you hear “95% accuracy”, you might think it comes in a uniform distribution of errors. However, that’s not the case.
Speech recognition systems often manifest error density in these specific categories:
- Low-frequency vocabulary
- Domain-specific terminology
- Proper nouns and entity names
- Numerical values and dosage information
- Short functional words such as negations
The result is a structural problem in which transcripts initially appear clean, though upon thorough review, a fraction of the transcript containing critical meaning is found to be distorted. Put simply, the most important information is the most vulnerable.
Where AI Transcription Errors Cluster
It is important to stress that these pattern-based inaccuracies are tied to language structure and ambiguity. Here are the high-risk categories:
| Error Zone | Typical AI Failure | Impact |
| Drug names | Substitution with similar-sounding terms | Incorrect medical interpretation |
| Numbers | Digit misrecognition or rounding | Financial or dosage errors |
| Proper nouns | Incorrect or invented names | Identity or record mismatch |
| Negations | Omission of “not,” “no,” or “never” | Reversed meaning in legal or clinical statements |
| Technical terms | Word substitution | Loss of precision |
This becomes significantly problematic because these sections carry the highest information load. And unlike filler words, they are structurally decisive.
Why the Final 5% Carries Disproportionate Risk
So the risk is not about how often errors occur, but rather about how serious the consequences are when they do happen.
In the medical field, even a single incorrect word can change the direction of treatment. The same idea holds in the legal field, where a missing negotiation in testimony can invert intent, or a misheard number in a compliance report can change regulatory outcomes.
Industries where precision and accuracy are critical must never treat transcription as a purely automated process – though it can still be integrated, provided it has a proper verification system.
In these environments, court transcription services, for example, are not merely a conversion of speech to text. It is the preservation of evidentiary meaning.
Domain Sensitivity Changes Everything
Transcription errors are either bad or catastrophic. It can be tolerable in some informal content, whereas that same standard is unacceptable for professions and sectors such as:
- Deposition transcription services
- Medicolegal transcription services
- Government transcription services
- Academic transcription services
AI systems are not reliable enough, especially for capturing the human essence of the distinguished professions mentioned, and a transcript would require thorough human review to be usable.
Why Errors Feel Rare Yet Are Operationally Significant
AI transcription excels in perceived fluency, wherein outputs read smoothly, creating an impression of correctness.
This is a cognitive bias problem. Transcription errors produce grammatically sound documentation, while the content’s meaning is likely altered. Coherence does not automatically equate to accuracy.
For example, a sentence can remain fluent even when a negation is removed or a numerical value is altered. This makes errors harder to detect without thorough verification. This results in operational overconfidence, where systems appear reliable until they are tested.
Transcription Prices and What Drives Real Cost
Transcription pricing is not determined solely by audio length. There are other unseen costs, and these are:
- Audio quality and clarity
- Number of speakers
- Technical terminology
- Turnaround time
- Verification and formatting
The cost reflects guaranteed accuracy (not all transcription companies) despite constraints, and not only speed alone. The more complex the audio, the longer the review time, thereby increasing costs.
Why Clients Choose Ditto for Accessible Transcription Services
Transcripts are not about converting recordings into text. It is about creating transcripts people can trust.
At Ditto Transcripts, we help clients turn audio and video recordings into accurate, readable, and professional transcripts for different sectors.
Here is what Ditto offers:
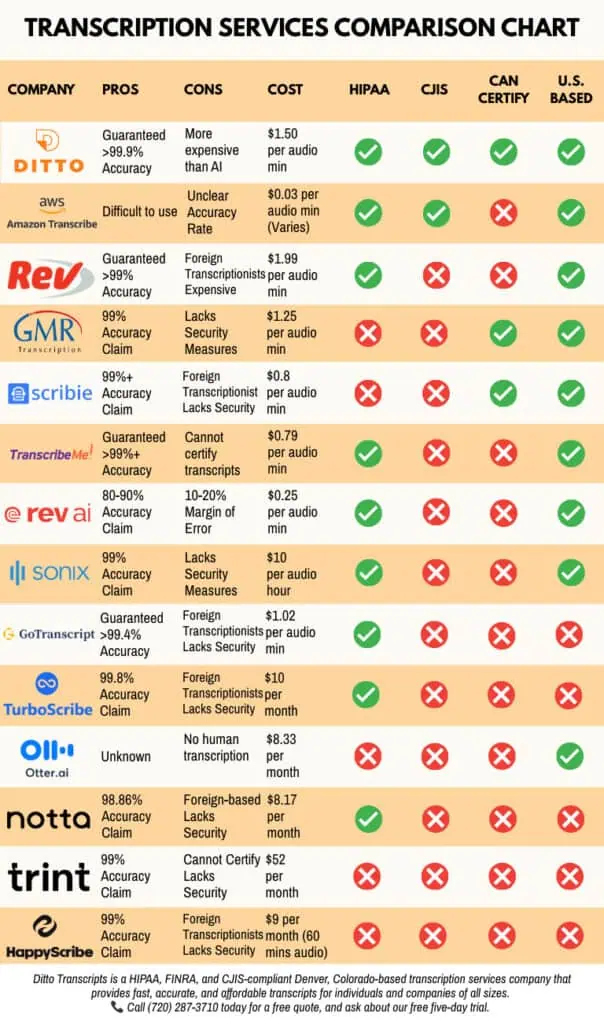
- Accuracy: Unlike AI alternatives, we guarantee 99.9% accuracy in our transcripts.
- Human transcriptionists: Ditto only hires professionals trained to handle complex audio.
- Support for accessibility needs: We offer flexible, comprehensive, professionally formatted transcripts.
- Industry-specific experience: Ditto supports different fields, including legal, medical, law enforcement, and other projects.
- Secure handling: Ditto Transcripts is HIPAA-, CJIS-, and FINRA-compliant, so we prioritize confidentiality.
- Flexible legal transcription pricing: Clients can choose from our turnaround and pricing options based on their needs.
- No long-term contract required: Clients can use Ditto for one project or ongoing transcription needs, no strings attached.
- Client testimonials: Need we say more?

The Real Problem With “Good Enough” Transcription
The biggest limitation of AI transcription is not that it produces incorrect output, but rather that it produces mostly correct output with occasional failures, making the final 5% incredibly consequential. Rather than being random noise, it is a distortion in information-heavy zones.
When transcription is for casual use, this may be acceptable. When it becomes part of a legal, medical, or regulatory record, the tolerance for uncertainty collapses. In those environments, the question is not how often the system is right. It is whether it is wrong in places that matter.
Ditto Transcripts is a Denver, Colorado-based transcription services company that provides fast, accurate, and affordable transcripts for individuals and companies of all sizes and is FINRA-, HIPAA-, and CJIS-compliant. Call (720) 287-3710 today for a free quote.