

According to recent transcription statistics, AI speech recognition still lags behind human accuracy. While AI transcription has advanced, statistics show it hasn’t yet met the 99% accuracy gold standard that a human transcription company can provide.
Up until now, statistics show that AI is at least 61.92% accurate in transcription. But, I wasn’t so sure about that – in all settings. In fact, I’ve always found it fascinating that the speech-to-text program on my iPhone rarely gives me any problems when I dictate notes, such as my grocery list. Would a physician have the same results?
And, where’s the disconnect in values coming from? Would my anecdotal evidence translate to anything tangible if I say, created a study to measure the different performances of AI vs. human transcription platforms? These are the questions that served as the basis for this study’s thesis.
In this, I created a fair testing environment. I used real-world metrics to compare the statistical performance of the top AI transcription platforms against each other, utilizing human-made transcripts that were verified to be more than 99% accurate—similar to those produced by legal transcription services from Ditto.
In this article, you’ll learn how:
- AI transcription platforms average only around 61.92% accuracy, compared to the consistent 99%+ accuracy delivered by human transcriptionists.
- Background noise, multiple speakers, and lack of contextual understanding cause AI to fail in real-world transcription tasks.
- Professional human transcription requires minimal editing and is still the better value for legal, medical, and compliance-sensitive applications. Our detailed study compares top AI transcription services head-to-head using real-world audio and reveals their performance gaps against expert human transcription.
Why Accuracy Matters: A Statistical Perspective
Before we proceed with the study on AI vs. human transcription, I want to set the context—and the stakes.
Transcription is the process of converting audio recordings into written text, and it plays a vital role across multiple industries. In law enforcement, it’s used to document body cam footage, recorded interviews, 911 calls, and police reports. In the legal field, deposition transcription services ensure every spoken word during court proceedings and testimonies is captured accurately for the record.
In medicine, transcription supports patient care through detailed documentation of visits, discharge summaries, operative reports, and clinic notes. Beyond these sectors, businesses, academic institutions, and content creators are increasingly turning to transcription to improve accessibility, accuracy, and workflow efficiency.
Here are some of the most common consequences of inaccurate transcription:
- Miscommunication
- Legal and compliance issues
- Loss of credibility and trust
- Reduced accessibility for individuals with disabilities
- Financial losses due to errors
- Compromised decision-making
- Negative impact on brand reputation
- Breach of confidentiality
- Misinterpretation in medical or legal contexts
- Poor user experience and satisfaction
A powerful example of the seriousness of these consequences is the Alabama medico-legal case, where a transcription error changed a patient’s insulin dosage from eight units to eighty. The mistake led to severe harm and, ultimately, the patient’s death, which resulted in a $140 million settlement.
This tragedy underscores the importance of medico-legal transcription services, which balance medical accuracy with legal accountability to ensure that every dictated word is accurately captured, verified, and safeguarded from costly errors.
Real-Life Examples
Now, it can be easy to dismiss these consequences as fearmongering to push a service. While I wish I could say it’s all well and good and that incorrect transcripts only lead to moderate embarrassment or maybe a slightly funny anecdote around the office, the consequences are heavy and far-reaching. Here are a few:
| Sector | Incident | Impact |
| Legal | Carlos Ortega Case | A 66-year-old pilot from Bogotá was wrongfully arrested and imprisoned for a year due to a transcription error that misidentified him in a wiretap recording. |
| Law Enforcement | Cody deShields Case | A prisoner was released 33 years too early due to an incorrect transcript (36 months instead of 36 years) and was only recaptured when he committed another set of serious crimes. |
These real-world cases underscore the importance of trial transcription services. In courtrooms, even the most minor transcription mistake can alter testimonies, influence verdicts, or jeopardize appeals. Professional trial transcriptionists ensure every statement, pause, and exchange is captured with precision, providing an accurate record that upholds the integrity of the legal process.
Speech Recognition and Artificial Intelligence Transcription
Speech recognition has been around since the 1950s, and the technology has developed just as much as everything else we have today. Theoretically.
Meanwhile, artificial intelligence, a new and wildly popular technology today, should improve speech recognition to dizzying degrees.
So… why hasn’t it?
Recent studies from 2021 have shown that the best speech recognition platforms can achieve only 61.92% accuracy in transcription tasks. Now, you might have experienced using voice-to-speech programs to dictate on your phone and think that 61.92% is low and not reflective of your experience—and you’d be right.
However, a vast majority of recordings that require transcription involve conversations between two or more people. Here, the inherent issues with speech-to-text become painfully apparent.
Multiple overlapping voices result in a run-on transcription that lacks coherence. Background noise can completely derail the automatic transcription. It also has no contextual understanding of the recording—as humans do—so it cannot transcribe when the audio is unclear, even if the words are clear to human listeners.
In sensitive and complex tasks, the AI vs human transcription conundrum has an easy answer—the one with the fleshy bits wins. We’ve known all this before… but what’s a claim without proof?
So, I intended to find out myself.
Human vs AI Transcription Study Introduction and Hypothesis
Tech companies often claim up to 95–99% accuracy for AI. However, real-world statistics tell a different story. Indeed, statistics from speech recognition benchmarks show that most AI transcription services have an average accuracy rate of only 70–80%. That’s why I hired and tested eight of the most prominent speech recognition and AI transcription platforms for this study to see how they stack up. The platforms, in no particular order, are:
- Otter.ai
- Rev.ai
- TurboScribe
- Notta
- Amazon Transcribe
- Sonix
- Trint
- Microsoft Speech Recognition
I either took their free trial offering or paid the fee requested by any new customer.
As for the hypothesis, well, that’s simple:
AI-powered transcription cannot match the accuracy of human transcription services, as they struggle with overlapping speech, background noise, and contextual understanding, resulting in text that cannot be used in critical transcription tasks without significant human intervention.
Significant human intervention in this context is having to correct more than 20% of the transcript to make it workable. In short, they need to score more than 80% on the accuracy test.
Since I signed up for these services, I will also quickly review each platform from a prospective client’s perspective.
Methodology
To construct this study, I acquired 14 recordings and transcripts from varying industries rated 99% accurate by Ditto’s transcribers, proofreaders, quality assurance experts, and—more importantly—our clients.
Here are the recordings:
| Test Recording No. | Industry | No. of Speakers | Description |
| 1 | General | 1 | Short monologue |
| 2 | General | 2 | Podcast |
| 3 | General | 2 | Podcast |
| 4 | General | More than 20 | City Council Meeting |
| 5 | General | 2 | Podcast |
| 6 | Legal | 8 | Congressional Testimony |
| 7 | Legal | 6 | Congressional Testimony |
| 8 | General | 2 | Podcast |
| 9 | General | 2 | Podcast |
| 10 | General | More than 20 | Board Meeting |
| 11 | General | More than 20 | Board Meeting |
| 12 | General | 2 | Podcast |
| 13 | General | More than 20 | Board Meeting |
| 14 | General | 18 | Board Meeting |
These transcripts are verbatim and have been sent out and used for various tasks. I cut the recordings to 15 minutes, submitted them to the AI transcription platforms, and got their resulting transcripts.
Then, using Ditto’s Text Comparison Tool, I compared the 99%-accurate transcript’s first 500 words or until a natural stopping point in the conversation (such as the last sentence of a specific speaker around roughly the five-minute mark) with the same section from each platform’s results and took the accuracy rates. These recordings are an excellent representation of what a transcription service handles daily, so this evens the playing field.
Transcript Editing and Standardization
I took certain steps to make this AI vs human transcription test as fair as possible.
It’s important to note that the transcripts received from the AI platforms were not edited in any meaningful way. Sentences were kept in their original presentation as much as possible, and the sequence of words as presented was preserved. Run-on sentences were also kept, and no punctuations were added.
To provide a more accurate comparison, however, several changes were made:
- Speaker labels and timestamps were removed. This was done to standardize the test, as not all AI transcription platforms had them. And even if they had them, the speaker labels were often vague (unnamed) and incorrect (one of the tests specifically had “2 speakers” in the title, and somehow, the AI transcript had three speakers instead.) This works in favor of the AI transcription platforms.
- The paragraph sequence of the AI transcripts was changed to match the accurate transcript. That means each paragraph starts and ends with the same word as much as possible. Capitalization and punctuation, or lack thereof, were preserved as is. Each paragraph ends with a blank line.
- Numbers were converted according to the accurate transcript. So, if a passage says “7” on the AI transcript, this was changed to “seven.” Furthermore, the format of large numbers was changed to match, i.e., from 1000 to 1,000. Multiple numbers, like phone numbers, are edited to reflect the same format, i.e., from 1-5-4-4-6-7 to 154-467 across all transcripts.
- Dashes, double dashes, or em dashes that denote hesitation, pauses, or stuttering were removed from the accurate and AI transcripts, as they tend to be subjective formatting choices. They were replaced with single spaces instead.
- Double spaces were removed from all the transcripts.
What About Word Error Rate?
Conventional transcription accuracy methodology dictates that Word Error Rate (WER) is used in all matters of speech recognition transcription. This test is heavily utilized in automatic speech recognition (ASR) and is the primary metric for accuracy in AI-driven speech recognition.
WER is calculated as:
Word Error Rate = (Substitutions + Insertions + Deletions) / Number of Words Spoken
However, I felt that WER was not enough for this test. Two of the biggest criticisms about WER are that it 1) does not accurately reflect human understanding and 2) is insensitive to context.
Consider this: when reading, how often have you encountered an erroneous word you did not expect to be in that particular line of text?
The typical human response here would be to stop and consider, then reconstruct the passage to either fit the word or find a more fitting word, perhaps similar to the typo. Often, this leads to a decreased reading experience, which, in many cases, is enough to convince the human in question to stop reading the material altogether (I know I would).
Besides, WER isn’t even applicable to traditional transcription, so it does not fit in an AI vs human transcription test.
Examples
For another, more tangible example, consider this passage from Test 4:
Speaker 1: “Councilmember Hudson.
Speaker 2: “Here.
Speaker 1: “Madam Mayor, you have a quorum.”
This is quite easy to parse. The speaker is taking a roll, ending with Councilmember Hudson, who replies in the affirmative. Then, they address the mayor, stating that the minimum number of members is present to move forward with the proceedings.
Now, consider this erroneous transcription:
Speaker 1: Yeah. Councilmember Hudson, you’re not a mayor.
Speaker 2: You have a quorum.
In this iteration, the speech recognition platform missed the word “here” and considered the first half of the third initial sentence part of the previous speaker’s dialog. This results in an oddly confrontational statement, “Councilmember Hudson, you’re not a mayor,” which does not fit into the conversation.
If this error were found within a 475-word transcript, it would represent a 0.83% word error rate.
However, to the discerning human reader, this would create confusion and distrust in the text. Such errors can change how a statement is perceived and have massive implications in transcription, especially for critical documents in law enforcement, legal, or medical fields.
By only identifying substitutions, deletions, and insertions and dividing them by the number of words spoken, WER gives a numeric value that does not directly equate to the human reading experience and the expected utilization of the transcript in any real sense. That’s why I didn’t use it.
Transcription Accuracy Statistics: AI vs Human
After submitting the same audio files to several AI transcription tools as well as to our human transcriptionists, here’s what the statistics showed:
- Mean AI transcription accuracy: 61.92%
- Accuracy range: 11.84 percentage points (lowest ~57.52%, highest ~69.36%)
- Human transcription accuracy: ~99%
These transcription statistics clearly show that automated speech recognition systems are inconsistent and far less accurate than professional human transcription.
Key Comparison Table
| Method | Accuracy Rate (Avg) | Error Rate | Notes |
| Human Transcription | ~99% | ~1% error | Ditto Transcripts in-house team |
| AI Transcription (Real) | 61.92% (mean) | ~38% error | Ditto study on real-world audio |
| AI Transcription (Typical) | 57–69% | 43–31% error | Industry averages |
| AI Transcription (Best-Case) | 85–95% | 5–15% error | Lab conditions / marketing claims |
The statistics speak for themselves: human transcription remains the gold standard for accuracy and reliability.And so, after a full week on this project, we have the answer to the question, “Can AI do well vs a professional human transcription company?”
Here are the results of the transcription accuracy test using Ditto’s Text Compare Tool:
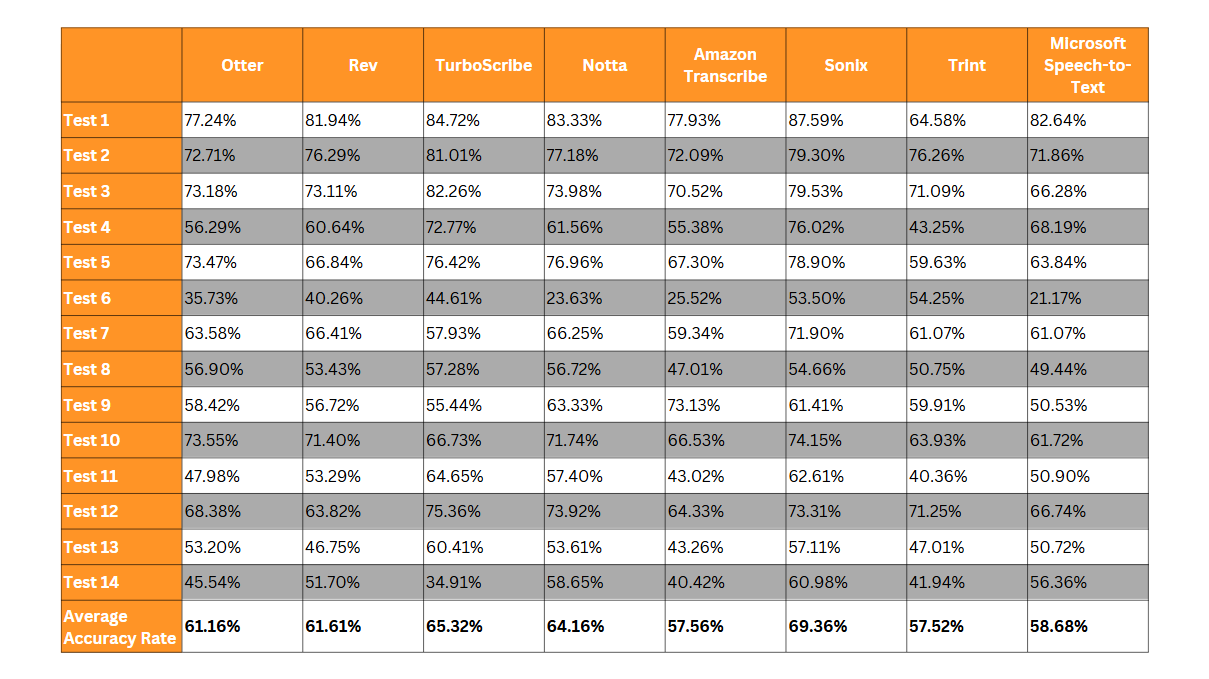
Sonix has the highest average accuracy rate at 69.36%. Sonix did reasonably well with recordings with multiple speakers compared to the rest.
On the other hand, Trint had the lowest accuracy rate at 57.52%, followed closely by Amazon Transcribe at 57.56%.
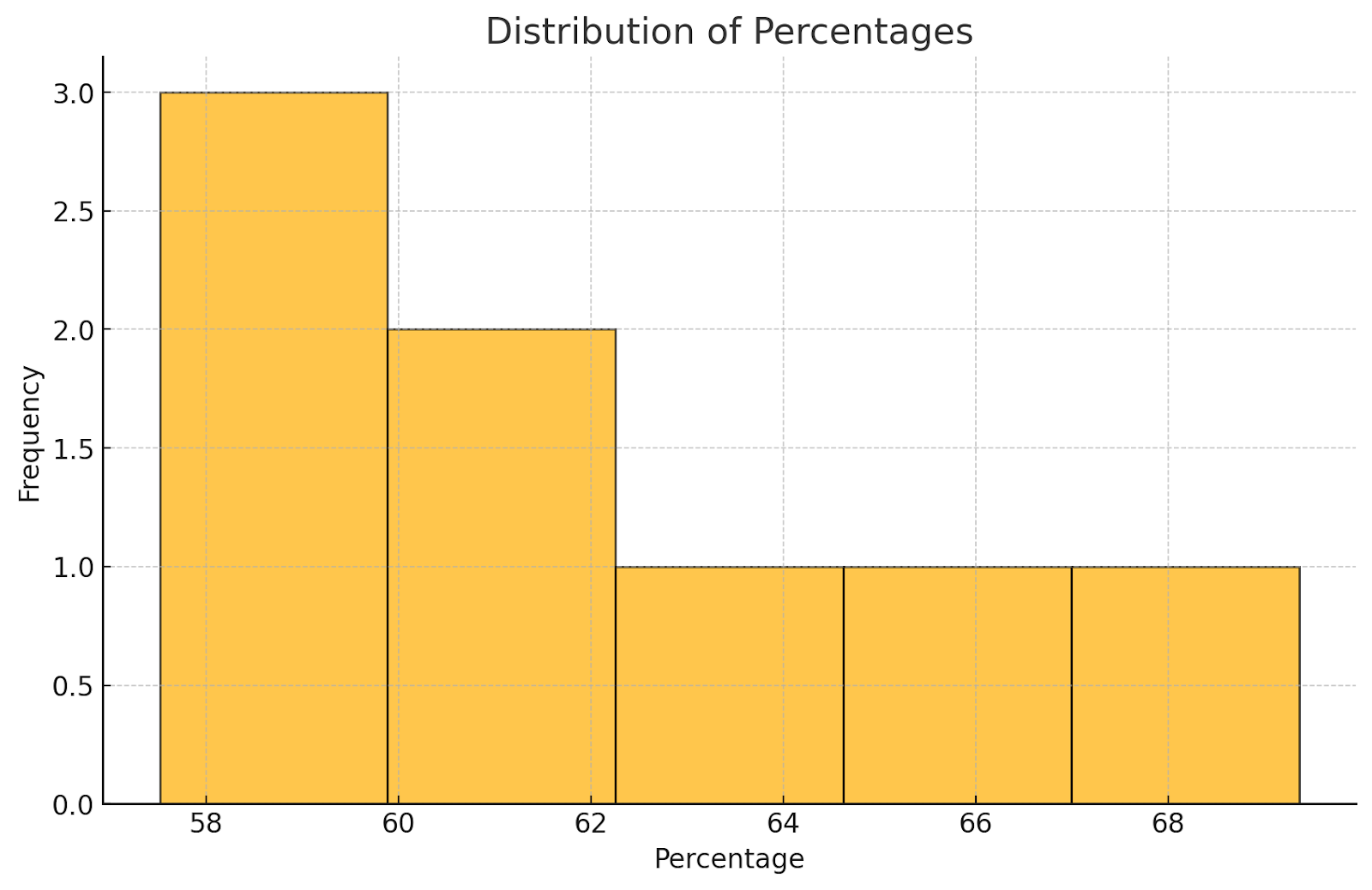
The accuracy percentage has a median of 61.39% and a mean (average) of 61.92%. The results were heavily distributed on the lower end, with an 11.84% difference from the highest to the lowest score. The standard deviation is also 3.90%, which means the accuracy rates are relatively tight around the average.
Margin of Error
The margin of error was found to be +3.25% to account for the instances when special characters were tagged as transcription errors. Here are the accuracy rates after considering that:
- Otter: 64.41%
- Rev: 64.86%
- TurboScribe: 68.57%
- Notta: 67.41%
- Amazon Transcribe: 60.81%
- Sonix: 72.61%
- Trint: 60.77%
- Microsoft Speech-to-Text: 61.93%
Findings and Interpretation of Results
Now that all the numbers are covered, we can move to interpretations.
After thoroughly reviewing the transcripts generated by these automated platforms, I noted several recurring issues that align with the working hypothesis. Here they are:
AI Transcription Has Trouble Transcribing Single-Word Sentences
Several test recordings were taken during council meetings, during which votes and motions are answered by saying “Aye.” AI transcribed these as “here,” “I,” “A,” or just completely ignored them.
AI Transcription Has Trouble Transcribing Multiple Voices
Tests 4, 6, 7, 10, 11, 13, and 14 involve more than two speakers. Overall, AI transcription scored lower in these tests.
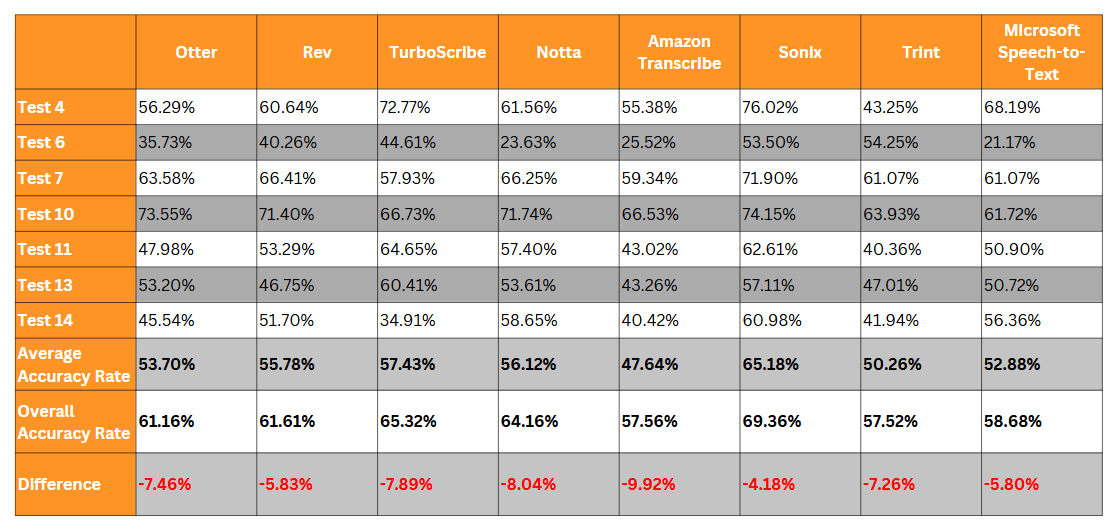
That is no surprise; AI transcription and speech recognition have long been known to have problems with multiple speakers.
However, not all these audio files have overlapping multiple speakers. Most of the time, they were just talking in turns.
This begs the question: does AI have issues with multiple voices, regardless of how the participants speak?
AI Transcription Still Has Trouble Transcribing Multiple Voices—Even If They Say The Same Thing
In Test 4, the speakers were called to recite the Pledge of Allegiance. It’s interesting to me that four companies (Otter.ai, Rev.ai, Amazon Transcribe, and Trint) did not transcribe the pledge. Notta and Microsoft Speech Recognition transcribed it poorly. Here they are, verbatim:
- Notta: “I complete allegiance to the God of the United States of America! And to the Republic which is, One nation, abroad, indivisible, with liberty and justice for all …”
- Microsoft Speech Recognition: “I pledge allegiance to the God. Obligations. Client. And two, which is 100. Either indivisible with liberty and us.”
Only TurboScribe and Sonix.ai transcribed the Pledge of Allegiance with reasonable accuracy.
This trend is seen in the rest of the tests that included the Pledge of Allegiance. The best results could be found in Test 14, where most AI transcription platforms transcribed or partially transcribed the section, with Sonix and Trint getting really close. Test 13, however, saw the worst result in the Pledge of Allegiance section, with none of the platforms managing to record it.
This shows that most AI transcription platforms cannot handle multiple overlapping voices, even if they’re saying the same thing. This supports the conclusion that AI transcription has problems with multiple voices, regardless of presentation.
AI Transcription Likes To Hallucinate
In Test 6, at the 1 minute 32 seconds mark, the speaker says, “I have, um, several people that are signed up to testify, and I thank you for (inaudible 00:01:36) testimony.”
Some of the AI platforms just did not transcribe that line. Some, however, did.
- TurboScribe: “I have a couple of people that want to find out who else is on, and I think we could address them later.”
- Notta: “I have several things like that that I signed up to. That’s fine. Thank you, sir. That’s fine. Thank you. Thank you.”
- Amazon Transcribe: “…and your both several people that are signed up to notify my address on.”
- Trint: “So people that I kind of feel comfortable and I can think of.”
Admittedly, the recording has poor audio quality. This happens in transcription; no matter how you spin it, you can do nothing about poor audio quality in the base recording. However, most human transcriptionists know better than to make things up.
AI Transcription Has Issues With Labeling
Speaker labels and timestamps were removed from all transcripts, but I would be remiss not to mention that AI has a significant issue with the former.
Some speaker labels were simply numbered, but these platforms cannot distinguish between three or more speakers. I had one transcript with three speaker labels when only two people were in the recording. Also, mid-sentence pauses are often identified as the end of the statement, and the continuation is shoved into the next line as the next speaker. This creates a disjointed narrative that does not equate to a great reader experience.
Bonus: Impressions and Gripes
So, that’s the result for this AI vs human transcription test, though we’re not done. As promised, here are some issues I encountered when signing up for these platforms’ free services.
Otter
I got the 7-day free business trial with no problems, though it annoyed me that it kept asking me to refer other people. Aside from that, uploading the recordings was very slow.
Rev
Rev offers free signup with no credit card details, AND it promises $6 in free credits (roughly 1,800 hours of free transcription).
However, I only got $1 when all was said and done.
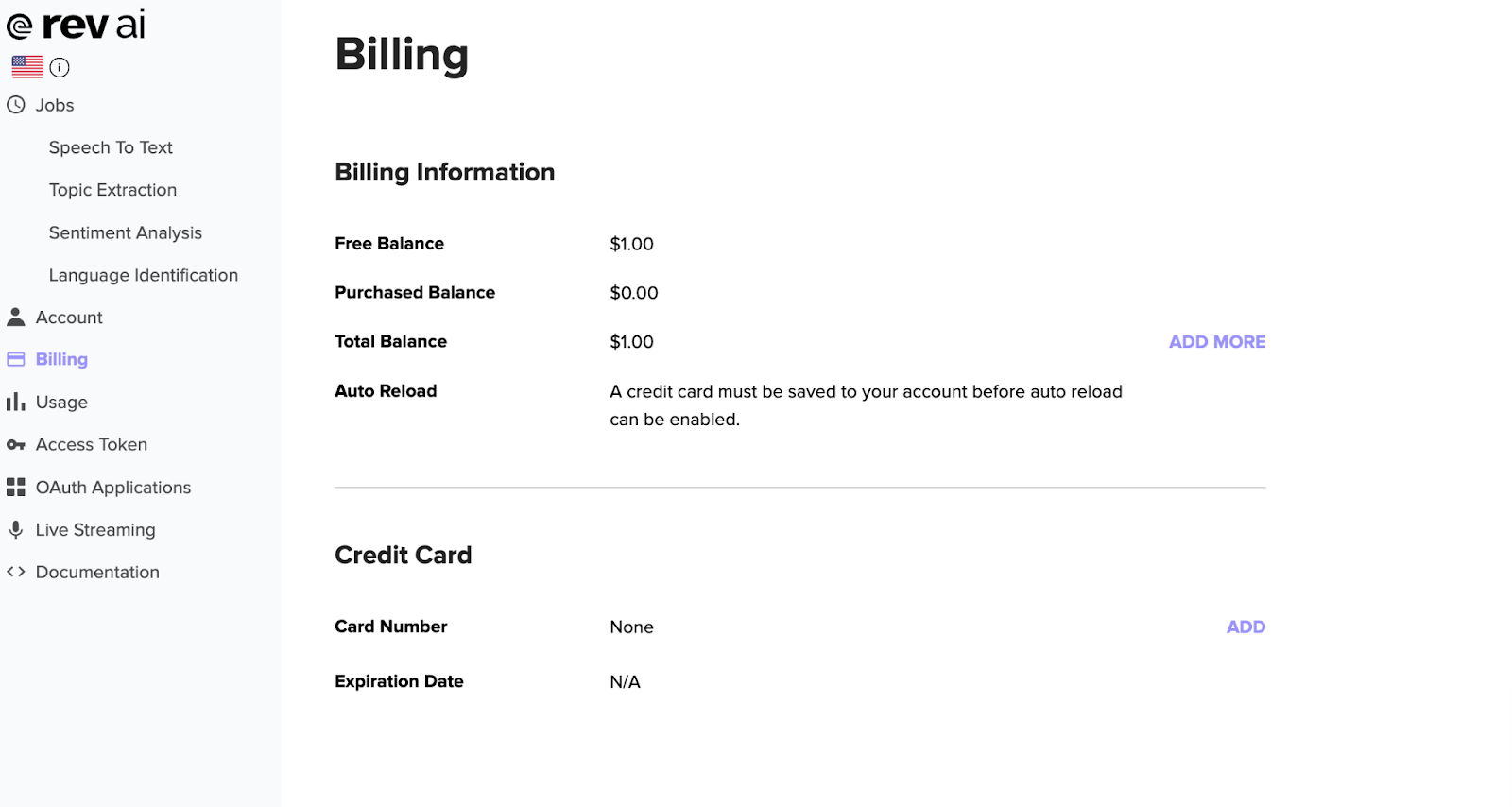
The platform also uploaded one file at a time, which made it more time-consuming.
Rev’s presentation as a HIPAA-compliant transcription provider is also confusing. In 2022, they announced that they were fully HIPAA-compliant via a blog post.
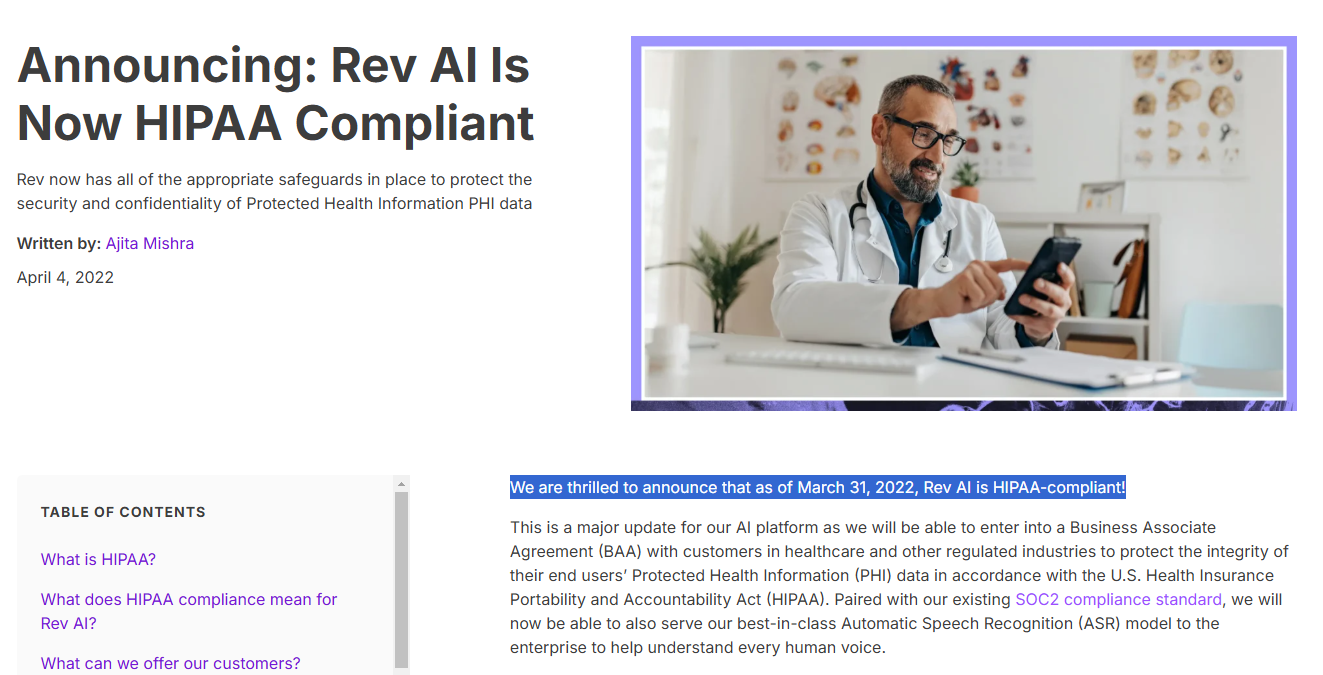
However, it turns out that its HIPAA-compliant transcription service is locked behind a different subscription, which in turn is hidden from general access and is only offered at the enterprise level.

There are so many hoops to jump through, and they only accommodate big clients. What a bother.
TurboScribe
This claims to be the most accurate platform in marketing and provides options to turn on speaker recognition, which did not work well with multiple speakers.
Notta
The platform didn’t accept some of my files due to length or format. I had to chop up some recordings to make it work.
Amazon Transcribe
It is one of the cheaper speech recognition options, though counterintuitive UI designs mire it and can be too complex for beginners. Files needed to be uploaded to the S3 bucket first, and they were transcribed one at a time. Not very efficient.
Plus, transcripts are downloaded as .json files, so you’d need to create documents in your preferred format to use them. Also, it seems to be deathly allergic to paragraphs, as all of its transcripts were in one big text block.
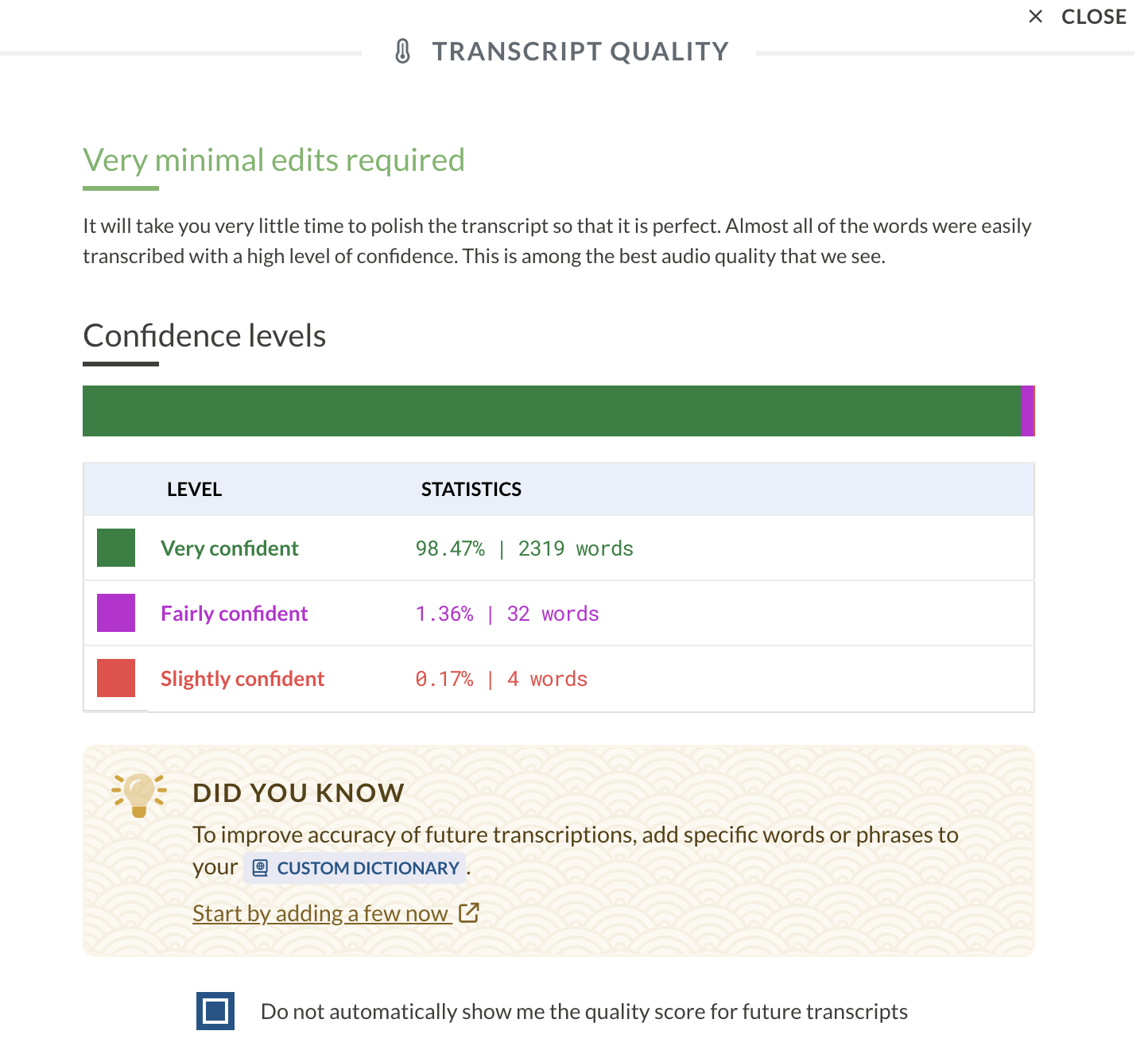
Sonix
It provides a snapshot of the expected transcript quality from the recording, which is a nice touch.
Trint
I had the easiest time with Trint from all the platforms here. I uploaded everything all at once and downloaded the transcripts in one click.
Microsoft Speech Recognition
The transcription platform requires a Microsoft 365 account and can be accessed via Word. Of course, that means uploading one recording at a time. To make matters worse, transcripts can only be downloaded as PDF files.
Conclusion: AI vs Human Transcription
Sonix takes the number one spot as the most presentable and accurate speech-to-text platform out of eight contenders, with an average score of 69.36% or 72.61% adjusted. (Previous data from 2021 had the average score at 86%, though that was based on the word error rate.)
This test was designed to replicate the real client experience when receiving AI-generated transcripts. In practical terms, obtaining a Sonix transcript is like completing 70% of the job, which isn’t bad for personal use, such as dictating notes or simple reminders.
However, when it comes to professional applications, that 30% gap becomes critical. In fields such as law, medicine, business, or law enforcement transcription, even a single error can alter the meaning, context, or legal implications. The primary purpose of outsourcing transcription is to save time; however, if an AI-generated transcript requires a full manual review, the time savings are negated.
| Aspect | AI Transcription | Human Transcription (Ditto Transcripts) |
| Average Accuracy | ~70% (Sonix) | 99%+ verified accuracy |
| Best Use Case | Personal notes, quick drafts | Professional and compliance-sensitive recordings |
| Performance in Complex Audio | Struggles with multi-speaker or technical content | Handles accents, jargon, and poor audio effectively |
| Editing Required | High – needs full manual review | Minimal – ready-to-use transcripts |
| Applications | Basic dictation | Legal, medical, and deposition transcription services |
Why Choose Ditto Transcripts

We did you a favor and compared today’s top transcription services side by side—so you don’t have to. Using key metrics like accuracy, cost, security compliance (HIPAA, CJIS, and FINRA), certification ability, and U.S.-based staffing, the results speak for themselves.
Among major players such as Rev, Sonix, GoTranscript, and Amazon Transcribe, Ditto Transcripts consistently comes out on top for accuracy, reliability, and data security.
| Metric | Ditto Transcripts Advantage |
| Accuracy | Guaranteed >99.9% accuracy, verified by professional human transcriptionists—not AI. |
| Compliance | Fully HIPAA, CJIS, and FINRA compliant—perfect for legal, medical, and law enforcement use. |
| Certification | Can certify transcripts for court and official documentation—something most competitors can’t offer. |
| Security | 100% U.S.-based team, ensuring sensitive recordings never leave the country. |
| Versatility | Expertly handles legal transcription, deposition transcription services, medical documentation, and more. |
| Transparency | Clear pricing at $1.50 per audio minute, with no hidden fees and unmatched quality assurance. You can explore more on our legal transcription prices |
Most transcription companies trade accuracy for speed or low cost. However, Ditto refuses to compromise. We combine human expertise with strict confidentiality and compliance standards to deliver transcripts that meet the highest professional expectations.
So, if you’re serious about transcription quality, the data has already made your decision for you. Choose Ditto Transcripts, where precision, compliance, and trust come standard. Don’t believe us? Check our client testimonials.
Ditto Transcripts is a Denver, Colorado-based FINRA, HIPAA, and CJIS-compliant transcription services company that provides fast, accurate, and affordable transcripts for individuals and companies of all sizes. Call (720) 287-3710 today for a free quote.